Another approach to interviewing..
The Art and Craft of Great Software Architecture and Development: My Favorite Java Developer interview questions
Monday, October 30, 2006
Monday, August 28, 2006
JDBC 3.0 Auto Generated Keys
One of cool feature in JDBC 3.0 is retrieving auto generated keys (autonumber/sequence) while inserting a row into the table. Until now we need to fire two queries one to execute the insert and the next to retrieve the sequence/autonumber of the inserted rows (in any order). It's quite obvious that this is not an efficient way as both the statement must be parsed, explain plan generated and executed. JDBC 3.0 makes it simple to retrieve the autogenerated keys with just one SQL, while inserting the row.
Here is an example.
In line 3 an int array is created to specify the column index of the auto generated key in the Insert SQL. In line 5 you pass the array created in line 3 as second argument to prepareStatement call. Once the query is executed you call getGeneratedKeys() method on the prepared statement object to retrieve the result set and then access this resultset to retrieve the generated keys.
This feature is supported from Oracle 10g R2 JDBC Drivers, not in previous JDBC versions (though this driver can be used for Oracle 9i as well). The ROWID is the default generated key retuned.
Here is an example.
- String insertSQL=
- "INSERT INTO client_info(client_id,first_name,update_time) values (client_id.nextval,?,systimestamp)";
- int[] keys={1};
- // retrieve connection
- PreparedStatement stmt=cn.prepareStatement(insertSQL,keys);
- int cnt = stmt.executeUpdate();
- ResultSet rs = stmt.getGeneratedKeys();
- rs.next();
- clientIdKey=rs.getInt(1);
In line 3 an int array is created to specify the column index of the auto generated key in the Insert SQL. In line 5 you pass the array created in line 3 as second argument to prepareStatement call. Once the query is executed you call getGeneratedKeys() method on the prepared statement object to retrieve the result set and then access this resultset to retrieve the generated keys.
This feature is supported from Oracle 10g R2 JDBC Drivers, not in previous JDBC versions (though this driver can be used for Oracle 9i as well). The ROWID is the default generated key retuned.
Thursday, June 01, 2006
Detail Formatter in Eclipse
Detail Formatter in Eclipse
While debugging the code, we put breakpoints in the code to see the value of a particular variable at that point. If the variable we are interested is a simple type we can easily see the value at the display frame but most of the time we need to look through the objects like Collection. Below code shows the composition of Hashtable.

If you select the collection variable on Debug mode the display frame will show something similar to this

If you want to see what is the value stored inside the Hashtable you need to navigator through the hierarchy like below

Needless to say it's laborious and boring task. Not a problem with Eclipse anymore!!!. If you know what the collection contains then you can see the value at the display frame without navigating through the hierarchy. Right click on the variable name in Variables panel and select "New Detail Formatter..." a new frame pop's-up. In the formatter frame enter the below code

Code inside the Detail Formatter:
Now if you select the variable again you can see the content of the Hashtable in the display frame without navigating through the hierarchy:
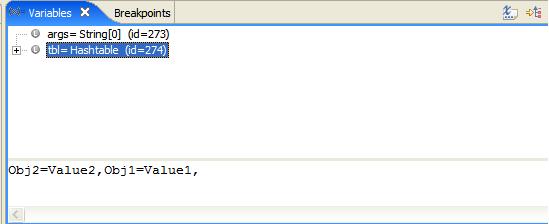
While debugging the code, we put breakpoints in the code to see the value of a particular variable at that point. If the variable we are interested is a simple type we can easily see the value at the display frame but most of the time we need to look through the objects like Collection. Below code shows the composition of Hashtable.

If you select the collection variable on Debug mode the display frame will show something similar to this

If you want to see what is the value stored inside the Hashtable you need to navigator through the hierarchy like below

Needless to say it's laborious and boring task. Not a problem with Eclipse anymore!!!. If you know what the collection contains then you can see the value at the display frame without navigating through the hierarchy. Right click on the variable name in Variables panel and select "New Detail Formatter..." a new frame pop's-up. In the formatter frame enter the below code

Code inside the Detail Formatter:
StringBuffer buff = new StringBuffer();
Enumeration enum = this.keys();
while(enum.hasMoreElements())
{
Object key = enum.nextElement();
java.lang.ref.WeakReference obj = (java.lang.ref.WeakReference)this.get(key);
Object internalObj = obj.get();
buff.append(key.toString()+"="+internalObj.toString()+",");
}
return buff.toString();
Enumeration enum = this.keys();
while(enum.hasMoreElements())
{
Object key = enum.nextElement();
java.lang.ref.WeakReference obj = (java.lang.ref.WeakReference)this.get(key);
Object internalObj = obj.get();
buff.append(key.toString()+"="+internalObj.toString()+",");
}
return buff.toString();
Now if you select the variable again you can see the content of the Hashtable in the display frame without navigating through the hierarchy:

Friday, May 26, 2006
Better coding?
Better codes?
Better code!!! I guess I am crazy but it forces out of me whenever I see what mess the application code has become these days. Colleges most often teaches about O(n) and algorithms. Four years after my college, I have never heard about O(n). I wonder does it make sense in times of bloated software's. On one side Microsoft & Sun has made the coding so easy but on the down side they sort of made the application developers dumb. Programming paradigm changed so radically on late 90's, the mantra these days is about knowing the API and application development has sort of become assembly lines in a manufacturing industry. I didn't anticipate this when I aspired to major in Computer Science (way back early 90's). Isn't programming about fun and creative? or do I miss something?... Today I got so frustrated which forced me to spill out this.
- Thou shall always write modular Class that exhibits high cohesion and less coupling
- Thou shall not create Collections with default allocation and waste memory.
- Thou shall not abuse call by reference
- Thy must program to interface
- Thou shall not have deep class inheritance hierarchy
- Thou shall not solely interrupt Object Oriented Programming as code reuse.
- Thy must remove the deprecated code and keep the code clean.
- Thou shall be knowledgeable on richness of the language.
Better code!!! I guess I am crazy but it forces out of me whenever I see what mess the application code has become these days. Colleges most often teaches about O(n) and algorithms. Four years after my college, I have never heard about O(n). I wonder does it make sense in times of bloated software's. On one side Microsoft & Sun has made the coding so easy but on the down side they sort of made the application developers dumb. Programming paradigm changed so radically on late 90's, the mantra these days is about knowing the API and application development has sort of become assembly lines in a manufacturing industry. I didn't anticipate this when I aspired to major in Computer Science (way back early 90's). Isn't programming about fun and creative? or do I miss something?... Today I got so frustrated which forced me to spill out this.
- Thou shall always write modular Class that exhibits high cohesion and less coupling
- Thou shall not create Collections with default allocation and waste memory.
- Thou shall not abuse call by reference
- Thy must program to interface
- Thou shall not have deep class inheritance hierarchy
- Thou shall not solely interrupt Object Oriented Programming as code reuse.
- Thy must remove the deprecated code and keep the code clean.
- Thou shall be knowledgeable on richness of the language.
Wednesday, May 17, 2006
Java goes opensource
Sun Microsystems Inc. at its JavaOne conference today announced that it would open-source Java but added that before it does so, company officials have to be certain the move won't lead to diverging paths in the code.
Richard Green, Sun's executive vice president of software, made it absolutely clear that Java would be open-sourced.
"It isn't a question of whether, it is a question of how," Green said to cheers from the developers on hand for JavaOne.
To give the announcement extra weight, Green described the plan in response to questions from Sun's new CEO, Jonathan Schwartz. The two men were on stage at the Moscone Center when the announcement was made.
The company did not set a schedule for when the open-source release would take place and said some problems first have to be resolved.
"There are two battling forces here: There is the desire to completely open this up, complete access -- and so many changes in the licenses have been made that it's virtually all there," said Green, referring to the licensing models now available to developers.
He also said compatibility is a major issue with the planned move. "I don't think anybody wants to see a diverging Java platform," Green said, arguing that one of the "great values" of Java is that the company has been able to avoid divergence and ensure consistency.
The challenge now, he said, is how to solve those issues. "I'm going to sign up big time to go figure that out."
Sunday, May 07, 2006
Lock free Concurrent Operations on Linked List
- It's possible to have a linked list data structure that is "non blocking" in a uni-processor multitasking environment. Though "block free" the data structure is not wait free. Block free datastructures are more performant than "synchronized" data structure.
"Non-blocking" data structures depends on the hardware capability to perform "Compare and Swap" (CAS) as atomic / uninterruptible operations.
Le'ts see the linked list creation and insertions.
Class LinkedList
{
LinkedList next=null;
Data data=null;
.....
}
LinkedList root = null;
Here "root" is global object and let's assume we have two process (P1 & P2) which work on this object concurrently.
First let's see the functions to manipulate LinkedList in single task environment:
boolean createRootNode(LinkedList root, Data dt)
{
LinkedList root =new LinkedList();
root.next=null;
root.data=dt;
return true;
}
boolean insertAfterNode(LinkedList item, Data dt)
{
LinkedList newItem = new LinkedList();
newItem.next=item.next;
newItem.data = dt;
item.next=newItem;
return true;
}
The same functions will look like below in a multi task environment using "synchronized" blocks
1. boolean createRootNode(LinkedList root, Data dt)
2. {
3. LinkedList newItem =new LinkedList();
4. newItem.next=null;
5. newItem.data=dt;
6. synchronized(root)
7. {
8. if (root==null) // Possible that prior executed thread could have created the Root item.
9. {
10. root=newItem;
11. return true;
12. }
13. }
14. return false;
15. }
16.
17.
18. boolean insertAfterNode(LinkedList itemAfter, Data dt)
19. {
20. LinkedList newItem = new LinkedList();
21. newItem.data = dt;
22. synchronized(itemAfter)
23. //Technically this is not foolproof implemenations.
23 // Other threads can delete itemAfter
24. // before it's synchronized here.
25. //Le'ts assume that the "entire datastructure" is locked
26. {
27. newItem.next=itemAfter.next;
28. itemAfter.next=newItem;
29. }
30. return true;
31. }
Synchronized blocks avoids data corruption/inconsistency in data but it blocks other threads from updating the data structure when one thread is inside the synchronized block. This delay is generally considered inefficient in real time systems as faulty thread will block non-faulty thread and the resources are not utilized to the maximum extent. So much research as be done on formulating "Lock free" datastructures. Below is one such implementation (Single Processor - Multitasking System).
CAS Code Snippet:
1. boolean createRootNode(LinkedList root, Data dt)
2. {
3. LinkedList newValue =new LinkedList();
4. LinkedList oldValue=root;
4. newValue.next=null;
5. newValue.data=dt;
6. return - atomicreferencefieldupdater.compareAndSet(root,oldValue,newValue);
7. }
8.
9.
10. boolean insertAfterNode(LinkedList itemAfter, Data dt)
11. {
12. LinkedList newItem = new LinkedList();
13. newItem.data = dt;
14. newItem.next=itemAfter.next;
15. if (atomicreferencefieldupdater.compareAndSet(itemAfter.next - ,newItem.next,newItem))
16. {
17. return true;
18. }else
19. {
19. newItem.next=null;
20. newItem=null;
21. return false;
21. }
22.
23. }
Here is how both the above functions works.
RootNode Creation:
createRootNode()- In this function a new node is created and initialized to the passed "Data".
- The function then calls "compareAndSet(root,oldValue,newValue)" function which does:
- compare the value stored in root with oldValue. If the values are same then "newValue" is assigned to root and CAS returns "true" if not CAS just returns "false".
Now assume that two process P1 & P2 tries to create root node concurrently.
Case- 1:
"Context Switch" happens on line 5 in P1
P2 completes creating the root
Result:
P1 fails in updating the root reference. Data structure is in consistent state.
Similarly for insertAfterNode() functions there are two possible inconsistent states
(*) itemAfter.next has been changed (by other process)
(*) itemAfter has been deleted (by other process)
Concurrent Insertion:
Initial structure
A -> E -> H
P1 - insert(A,"B")
P2 - insert(A,"D")
Both the process try to insert after A and only one can succeed.
Combination of context switch snapshot will be something like
P1 (started) - 12. LinkedList newItem = new LinkedList();
13. newItem.data = dt;
14. newItem.next=itemAfter.next;
/*
newItem->next & itemAfter-> next = "E"
*/
- -----------------------------------------------------------------------------
- P2 (Context switch)
- 12. LinkedList newItem = new LinkedList();
13. newItem.data = dt;
14. newItem.next=itemAfter.next;
/*
newItem->next & itemAfter->next = "E"
*/
------------------------------------------------------------------------------ - P1 (Context switch)
15. if (atomicreferencefieldupdater.compareAndSet- (itemAfter.next,newItem.next,newItem))
16. {
17. return true;
18. }
/*
nextItem->next="E" , itemAfter->next="B"
*/
- ------------------------------------------------------------------------------
- P2 (Context switch)
- 15. if(atomicreferencefieldupdater.compareAndSet(itemAfter.next,newItem.next
- , newItem))
- /* fails nextItem->next="E" but itemAfter->next="B" */
Similarly if Process 2 (P2) is executed to completion in one execution P1 CAS will fail and returns "false" and the linked list will look like
"A" -> "D" -> "E" -> "H"
Concurrent Insertion and Deletion:
Now let's see how "Deletion" works:
P1 inserts new element "F" after "E".
P2 deletes the element "E"
P1 (Started)
12. LinkedList newItem = new LinkedList();
13. newItem.data = dt;
14. newItem.next=itemAfter.next;
/*
newItem->next & itemAfter->next = "E"
*/
- ------------------------------------------------------------------------------
- P2 (Context switch)
- xx. LinkedList item2Del=param1.next;
xx. return CAS(param1.next,item2Del,item2Del.next); - /* P2 executed to the completion
- "A"->"B"->"D"->"H" ->"E->next=null"
Note: E cannot be GC'ed as the reference is still in P1
*/
-------------------------------------------------------------------------------------
P1 (Context Switch)
15. return CAS(reference,oldValue,newValue);
/* The above operations fails as
newItem.next="H" but itemAfter.next=null
*/
P1 has to be performed again.
References:
http://en.wikipedia.org/wiki/Compare-and-swap
http://citeseer.ist.psu.edu/herlihy93waitfree.html
It's quite unclear for me as how all this will work in a multiprocessor environment except to know that Multiprocessor environments uses some sort of semaphore/mutex to access the shared memory (if it's so then it's not truly lock free).
Friday, January 07, 2005
I came across an application from iReasoning. It was a MIB Browser. When I had my first look at it, i was not able to recognize that it was written in Java. When my folks told me that it was Java, I guess it should be using SWT. No! I was wrong again. IReasoning's MIB Browser doesn't look and feel like Swing. Teh UI was damn good and the response was excellent. I delved into the jars and found that it uses jGoodies.
Screen shot of iReasoning MIB Browser
Screen shot of iReasoning MIB Browser
{kind=link}
Well, almost one full year has passed by before I make my second post to this blog. Thinking about the contents of my previous, a smile creeps in my face. Sun is in a far better position that last year and yes, Java too is in a better position. Tiger is out and the road-map for Mustang is released. I would like to eat my previous blog's words, but let me wait for some more time to do that.
Subscribe to:
Posts (Atom)